Contrastive Active Inference
Presented at NeurIPS 2021



Learning a model
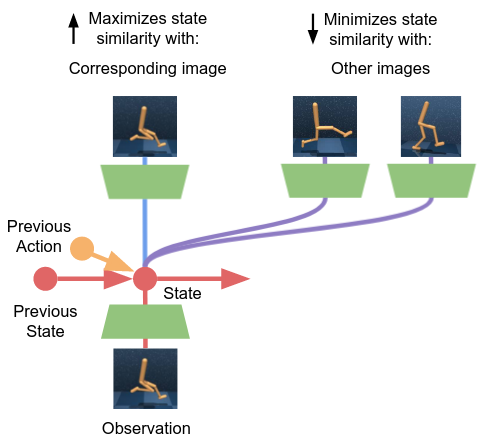
Our method, which we dubbed Contrastive Active Inference, is an Active Inference instantiation based upon Contrastive Learning. The objective of the agent is always to minimize its free energy. Though, the way it learns to do it it's based on Contrastive Learning.
In Active Inference, the brain first learns a model of the environment. This model should capture how the environment's state varies, due to the agent's actions. If we perceive the environment through high-dimensional signals, such as images, we may desire a more compact representation to model the environment's dynamics. This can generally be achieved by using a sequential VAE-like architecture, that learns to generate images that look like the environment's visual observations pixel-by-pixel.
In our method, the compact representation for the world model is, instead, learned by minimizing a contrastive version of the free energy objective, which we called contrastive free energy. By minimizing this objective, the model learns to associate the state of the environment's representation with the corresponding visual observation, while also making the state representation as distinct as possible from the other images. Similar and dissimilar pairs are selected contrasting observations across time and across different behavioral sequences.
Learning actions
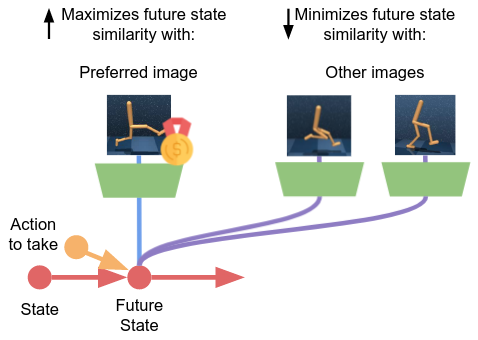
With respect to future actions, in Active Inference, we aim to find actions that will minimize free energy, by achieving preferences in an unambiguous way. If we use a VAE-like model for this, it implies imagining how the future will look like, by generating potential images of the future with the model, and computing the distance in pixel space. However, this can be quite problematic.
In the Contrastive Active Inference framework, the agent selects actions that minimize a contrastive objective that we dubbed contrastive free energy of the future. This objective enables causes the agent to search for actions that will lead it to states that have the highest similarity with preferences, while avoiding states that correspond to different images.
If you'd like to know more, read the full blog HERE.
Visual control




Citation
title = {Contrastive Active Inference},
author = {Pietro Mazzaglia and Tim Verbelen and Bart Dhoedt},
booktitle = {Advances in Neural Information Processing Systems},
year = {2021},
url = {https://openreview.net/forum?id=5t5FPwzE6mq}
}